










You probably don’t need to be in tech to know - or at least have felt - this week’s massive AWS outage.
AWS (Amazon Web Services) - a division of Amazon (AMZN) - is a massive suite of cloud computing services: computing power, storage and databases, predominantly for businesses, though also for individuals.
Instead of managing their own physical infrastructure, companies rent scalable resources from AWS.
To set the context, AWS is by far the most significant player in the cloud space with 30% market share, followed by Microsoft’s Azure (20%); with Google Cloud trailing at 13%.
The outage was for the most mundane of reasons - something I will come to - though the impact was enormous.
Apple Music, Zoom, Pinterest, Reddit, The New York Times, Adobe Creative Cloud and our own Canva significantly impacted.
Actually, that’s not fair: let’s do a roll call:
Social & communications: Snapchat, Slack, Discord, Signal, Pinterest: chats and shares stalled. SIGNAL!
Gaming: Fortnite, Roblox, Epic Games Store, VRChat, Steam: millions kicked mid-game.
Finance & shopping: Venmo (transactions frozen), Coinbase, Robinhood (crypto dipped 1-2%), Chime, Capital One, Instacart, Grubhub: payments and orders halted.
Work & rroductivity: Canva, Asana, Jira Software, Adobe Creative Cloud: workflows ground to a halt.
Entertainment & streaming: Prime Video, Amazon Music, Hulu, Disney+, Max, Tidal, IMDb, Roku: buffering and blackouts everywhere.
Amazon ecosystem: AWS itself, Amazon shopping: core services tanked.
And that’s only half the rollcall.
Famously, Twitter (I won’t call it X) did not go down, though that is because since 2023, they’re on their own infrastructure, something Elon truly boasted about as only Elon can. (In fairness, I got most of my updates on the situation from Twitter, so boast I guess!)
According to Ookla, +11m reports of impact were recorded.

I’m yet to find a credible report on the cost of such outages (AWS also went down in 2021 and 2023), though you’d have to figure we’re talking hundreds of millions if not billions in lost revenue.
We’re talking financial transactions, emergency responses, supply chains, bookings, sales; everything.
To be clear, I am an enormous fan of AWS and its infrastructure.
I am not being critical of it.
I do - on one hand - get the call for greater scrutiny - for such a concentration of our interconnecting economy. One mistake and a big part of the Internet collapses.
With AWS, the barriers to competition and innovation are significant.
Though I also understand how the Internet is built and that this is where we are at.
I’m not going to delve into whether the situation is right or wrong - clearly it’s fallable and tech concentration is a problem on many levels, and take from that what you want; though I am going to touch on the why this happened quickly and then my favourite part: the internet’s brilliant quips in light of the situation.
Why did AWS fail
I mentioned that the failure was for the most of mundane reasons.
And it truly was.
Mundane as it was, a significant chunk of the Internet just stopped working, and so it’s worth diving into why.
This wasn’t the work of hackers.
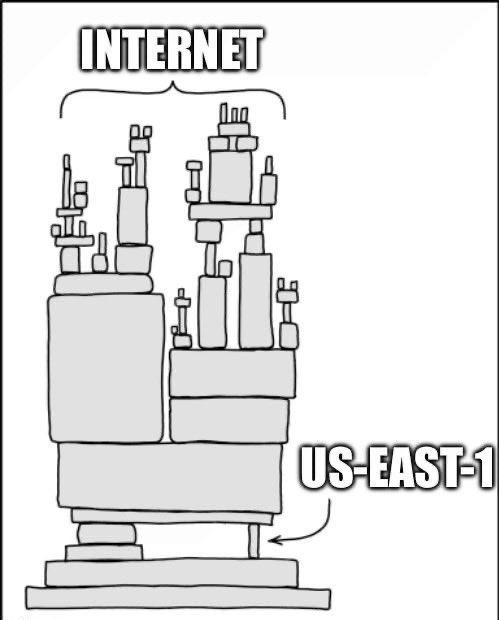
It was a DNS glitch in a single data centre (US-EAST-1) in Northern Virginia that cascaded into global chaos.
DNS is about as fundamental to the Internet as it gets. It’s the roadways, traffic lights and roundabouts that route traffic. In simple terms, it’s why we have IP addresses.
From experience, if it isn’t a hack, it’s almost always DNS.

At AWS, an internal monitoring system for network load balancers shat itself: inaccurate name-to-IP mappings corrupted the entire DNS chain and the system fell like dominos.
The concentration of US-EAST-1 is significant and anyone that uses AWS likely knowns that.
It’s the mothership of AWS.
Even if your AWS instance is in Sydney, it relies on US-EAST-1 in realtime.
The mothership goes down, we essentially all go down. (Multi-region backup aside, something I won’t bore you with, though you should be multi-homed on at least two clouds, not just geographically redundant - allowing yourself to have one point of failure.)
The internet has fun because… well… we had nothing else to do
I had plenty to go on, though the AWS downtime was also painful for us. Our clients were fine, though we rely on AWS, and their outage affected our work.
It did, however, give me a chance to keep a beat on what was happening on the ground, and it was as humorous as enjoyable to watch.
My favourite story was of Eight Sleep.
They’re a manufacturer of quite expensive beds that position you in the ideal position individually, allowing you to heat or cool the bed to your specification. And frankly, who knows what else?
Their beds rely on AWS. Exclusively.
Their CEO, Matteo Franceschetti, was quick to Twitter, apologising and promising remediation.
People didn’t buy it:
What the AWS outage pointed out, however, was that this was a bed that sends 16GB of monthly data (!) for sleep:
And it wasn’t just that beds stalled. They went ‘haywire’ without AWS.
Like sleeping sitting up. Being overheated. (A premium bed that sells for thousands.) (BYO fish tank cooler.)
Even water purifiers went kaput.
Plenty of IT admins had fun.
And there is an update from AWS itself, which is amusing.
James Hamilton famously ‘runs’ AWS from an engineering perspective. He lives on a custom yacht.
According to this AWS update, in four minutes he solved the issue after making landfall.
Not sure you could make this up.
Though the internet still had fun.
You can either laugh or cry. It was a thing, it is a thing, it’ll be a thing.
This is complexity at a level that one would need to write a book just to capture a glimpse.
There is redundancy for such events, and that is relatively easy. Though if you’re all on the deck whilst the orchestra plays, have some fun at the same time.

Related posts




Australia's trusted software development partner





